

提及玩“黑传闻”的电脑成就宿舍 自慰,公共齐在吹我方的4090显卡。
然而比4090贵了几十倍的H100,不异是“GPU”,为啥却不行用来玩游戏?

这个问题,猛一看,很弱鸡啊。
但问到具体原因,许多东说念主却说不出个456来。

今天我就简便捋捋,除了接口以外,其他更首要的原因↓
01、架构讨论的各异
最中枢的小数在于两者的架构各异,架构决定了互相的中枢智商不一样。
RTX4090聘任了N记的Ada Lovelace架构,专注于游戏和高档图形解决,这种架构在游戏性能上有贼拉牛B的优化,包括高档的图形渲染工夫如色泽跟踪和DLSS。

RTX4090统统包含 16384 个 CUDA 中枢和 512个第四代 Tensor 中枢,以及 128 个第三代 RT(色泽跟踪)中枢。
底下这个是其单个SM的架构图,4090由128个这么的SM构成。
 宿舍 自慰
宿舍 自慰
升迁游戏体验的几大黑科技,齐是靠这些核“肝”出来的。
比如光追效力主要依靠RT核,而DLSS包括抗锯齿、超隔离率、色泽重建等等,主要依赖Tensor中枢和CUDA中枢提供的AI增强图形效力。
玩烧机游戏的齐懂,开不开光追效力,体验全齐不一样。

而H100的则是基于Hopper架构,主要针对大边界并行解决和AI任务进行优化,而非图形渲染。
H100包括了16896个CUDA中枢和528个第四代Tensor中枢,提防,莫得对图像渲染至关首要的光追中枢(RT Core)。
下图是H100单个SM的架构暗示,H100由132个这么的SM构成。
骚女qq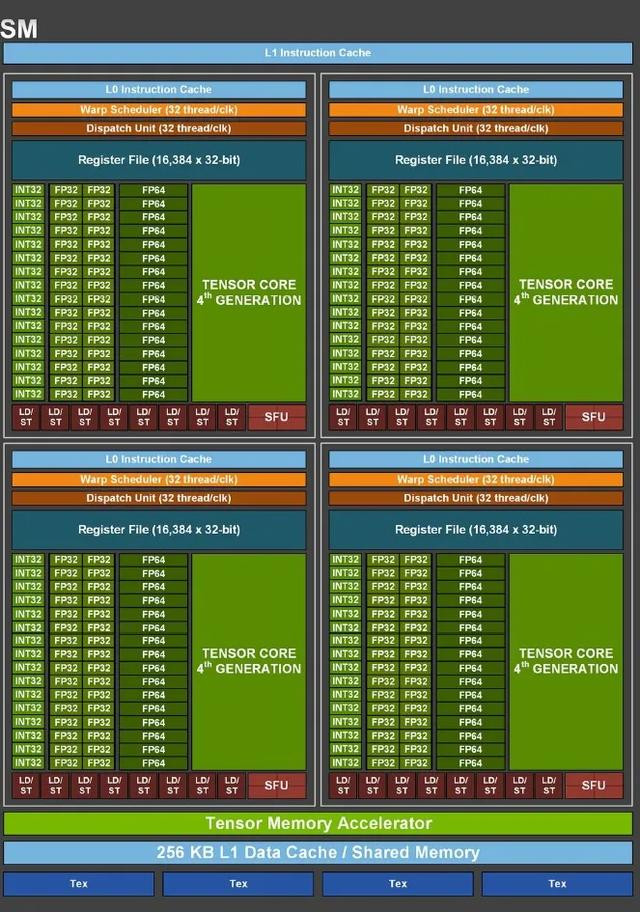
看对比图就发现辞别了,天然H100领有更多的CUDA中枢和Tensor中枢,但这些中枢是面向复杂计较和深度学习模子熟悉的。
比如,H100的CUDA中枢支捏FP64、FP32、TF32、BF16、INT8等多种数据类型的高效计较。
而4090的CUDA中枢就不一样了,东说念主家主攻图形密集利用,只针对单精度和双精度作念了优化。

02、运行和API的解救大不一样
H100除了内核优化和讨论的硬伤,还有一个大问题。
N记为游戏级GPU(也4090为代表的Geforce系列)提供了特等的游戏运行,优化游戏性能和兼容性。H100则莫得。
这等于导致H100无法支捏DirectX、OpenGL、Vulkan等主流游戏API(严格说是表面上支捏),也不支捏Unity、子虚、Godot这些主流的游戏引擎。
比如,黑传闻悟空聘任的等于子虚引擎5。

基本上,这两条就息交了拿H100玩游戏的任何念思。天然咱们不错堆砌一些意义↓
老本的问题:我一个4090齐买不起的小卡拉米,我会磋议拿贵几十倍的H100来玩游戏吗?
电源和散热的问题:H100的功耗和热输出讨论用于机架式做事器环境,对用游戏PC来说,有极大的挑战。

是以呢,4090这种GPU,不错叫显卡,能够图形加快卡。
而H100这种GPU,更准确的叫法其实是GPGPU(General-Purpose GPU),我更愿称之为AI加快卡。
好了,不扯了。
是期间把我的顾惜20多年的TNT2翻出来插上,畅玩《黑传闻悟空》了
 宿舍 自慰
宿舍 自慰